GPU as a Service (GPUaaS) for AI
NovaGPU: On-Demand GPU Power for Your AI/ML Tasks
Affordable, scalable GPU resources for small-to-mid-sized AI/ML workloads. Train models, run inference, and more—while keeping costs manageable.
Affordable, scalable GPU resources for small-to-mid-sized AI/ML workloads. Train models, run inference, and more—while keeping costs manageable.
Sustaining AI projects can be challenging, especially when returns take 2-5 years to materialize. Investing in costly dedicated GPUs too early can drain resources—particularly during the trial-and-error phase of selecting the right GPU. NovaGPU by IP ServerOne bridges this gap by offering GPU as a Service, providing on-demand access to high-performance yet affordable GPUs—from RTX 3090 and RTX 4090 to RTX 6000 Ada and H200 NVL—without the burden of upfront costs, complex setups, or infrastructure management. Designed for AI developers, researchers, and enterprises working with small-to-mid-sized AI models, NovaGPU enables seamless training, fine-tuning, and deployment. With flexible pay-per-use or subscription options, you can scale your AI projects efficiently. Fully managed and hosted in Malaysia, it ensures data sovereignty compliance while making AI development cost-efficient, scalable, and hassle-free.

Training complex models, running deep learning, natural language processing (NLP), or scientific simulations all require GPUs—an expensive upfront investment that creates a major barrier.

AI/ML workloads require specialized networking, storage, and compute resources, which can be challenging to configure optimally. Hardware failures and GPU degradation can disrupt operations.

For industries with strict data regulations, running AI/ML projects across borders is challenging. NovaGPU keeps your data in Malaysia, ensuring compliance with local laws and protection from cross-border risks.
When you’re focused on developing AI models or processing real-time data, worrying about data loss should be the last thing on your mind. With NovaGPU, you can have peace of mind with automated tiered backups:
Whether you’re recovering from unexpected system failures or safeguarding your evolving AI models, your data is protected at every stage.


NovaGPU provides affordable, high-performance GPUs with flexible pay-per-use or subscription models, ensuring sustainable costs and predictable pricing—perfect for long-term AI projects.

Easily scale GPU resources up or down to match your project needs, from small-to-mid-sized AI models to complex deep learning tasks, optimizing GPU usage and maximizing ROI.

Enjoy 24/7 support and hosting in a secure, high-availability Tier III data center so you can focus on your core business while we handle your infrastructure.

With 99.9% uptime guaranteed in our SLA, NovaGPU ensures reliable service, backed by data redundancy and automated backups, minimizing disruptions and data loss.

Access mid-to-high-end GPUs, including the NVIDIA H200 NVL, to speed up AI training, fine-tuning, and real-time inference—reducing iteration time and accelerating deployment.
NovaGPU balances performance, cost, and scalability for small-to-mid-sized AI projects, supporting diverse applications, from LLMs and generative AI to scientific simulations.

With NovaGPU, we handle hardware failures, repairs, and maintenance, freeing you from infrastructure management and allowing you to focus entirely on your AI projects.

NovaGPU ensures your data stays local, complying with Malaysia’s data sovereignty laws and global standards like ISO27017 and PCI-DSS, offering top-tier security and protection.
Unleash the full potential of your projects with high-performance GPU servers today.
Dream Big, Compute Bigger!
On-demand GPUs for AI/ML. From MYR1.96/hour for RTX 3090, MYR19.09/hour for H200 NVL.
NovaGPU protects your data with automatic backups every hour, day, and week, ensuring quick recovery in case of cyberattacks or disasters to maintain uninterrupted AI development and deployment.
With NVIDIA GPUs like RTX 3090, RTX 4090, RTX 6000 ADA, and H200 NVL, NovaGPU accelerates AI/ML training, fine-tuning, and real-time inference, efficiently handling complex AI workloads and deep learning tasks.
NovaGPU ensures high availability and data security with automatic redundancy across multiple data centers, minimizing downtime and safeguarding AI workloads from unexpected disruptions.
Designed for demanding AI/ML and high-performance computing (HPC) tasks, NovaGPU ensures high-speed training, precise inference, and reliable performance for complex models and custom applications.
Easily fine-tune your pre-trained models on NovaGPU, enhancing accuracy and performance for your AI applications in a secure, reliable local cloud environment.
Benefit from around-the-clock support from our experienced engineers, ensuring your GPU instances run smoothly, with quick issue resolution to maintain optimal performance.
Spin up GPU instances: Quickly launch GPU instances for AI workloads.
Resize on-demand: Scale resources to fit project needs.
Manage security access: Control access for secure operations.
Billing & Transactions: Easily manage payments and view billing details.
Hybrid Cloud Ready: Seamlessly integrate with hybrid cloud environments.
SSD Storage: Benefit from fast and reliable SSD storage.
HA Cloud Infrastructure: High availability with automated failover.
No Vendor Lock-in: Enjoy flexibility with no vendor restrictions.
NovaCloud Care: Managed service with additional charges.
Anti-DDoS Protection: Free 5Gbit/s protection against DDoS attacks.
Customizable Security Group: Easily configure firewall settings.
Key-based Authentication: Secure access with public and private keys.
Tier III Data Center: Hosted in a compliant Tier III data center with ISO 27001, ISO 27017, and SOC 2 Type II.
Flexible Pricing Models: Choose pay-per-use or subscription-based options.
Supported OS: Currently supporting Debian and Ubuntu.
Scalable On-Demand: Resize, rebuild, and scale your instance as needed.
Optimization Features: Shelve, unshelve, stop, reboot, and manage multi-volume and multi-snapshot attachments.
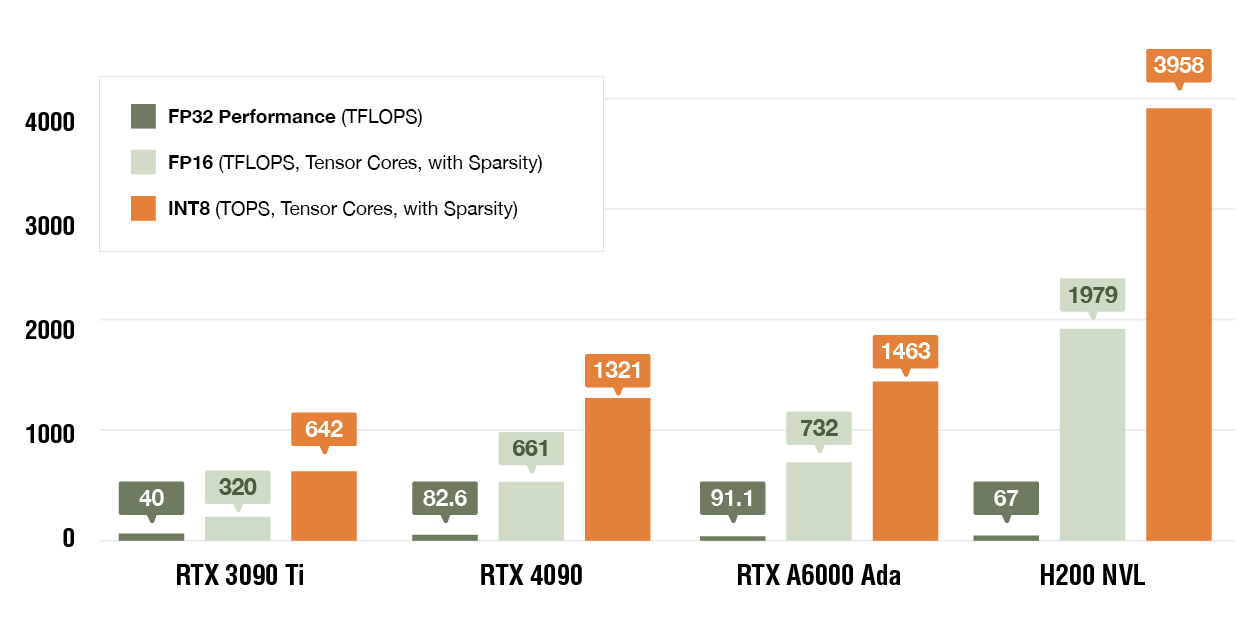
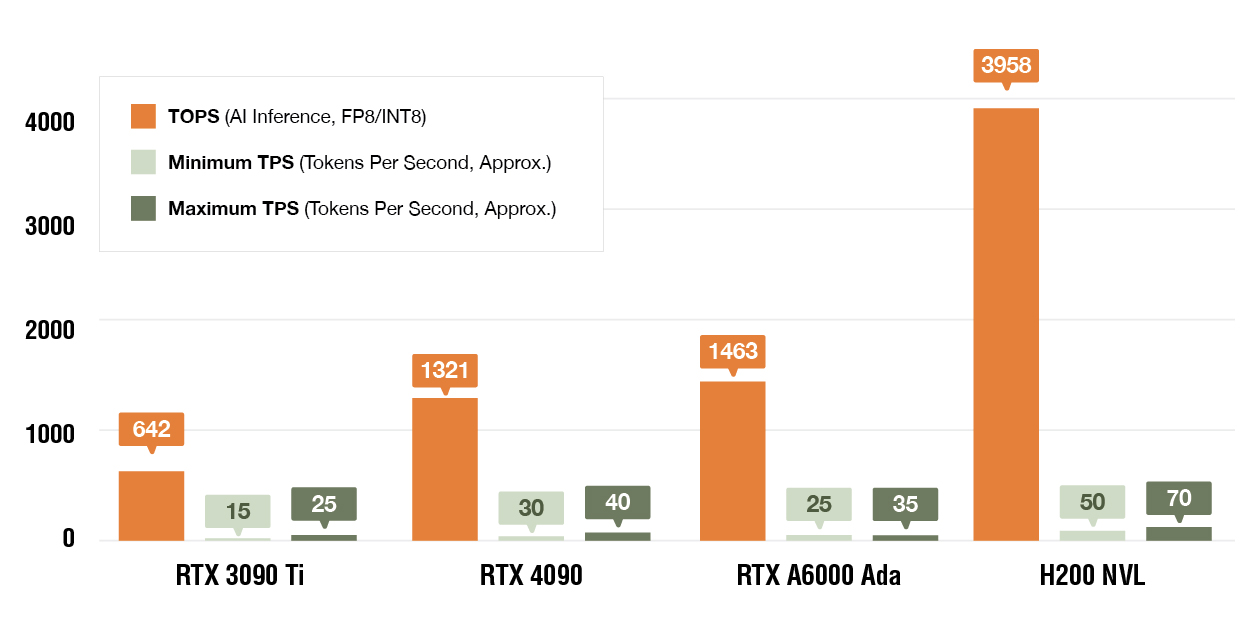
We offer a range of NVIDIA GPUs options to cater to your specific AI/ML needs:
The RTX 3090, based on NVIDIA’s Ampere architecture, is a consumer GPU with 24GB of GDDR6X VRAM and 328 Tensor Cores. It provides adequate performance for AI/ML workloads, content creation, and gaming, serving as a reasonable option for enthusiasts and solo developers working on moderately demanding tasks.
The RTX 4090, built on NVIDIA’s Ada Lovelace architecture, is a high-end consumer GPU with 24GB of GDDR6X VRAM and 512 Tensor Cores. It steps up compute performance for AI/ML workloads, gaming, and content creation, making it a solid choice for users needing more power and efficiency.
The RTX 6000 Ada, a professional-grade GPU from NVIDIA’s Ada Lovelace lineup, boasts 48GB of GDDR6 VRAM and robust compute power. It’s built for tougher tasks like AI, complex simulations, and 3D rendering, offering greater precision and capacity for advanced AI/ML users.
*Note: This option is available only on Bare Metal GPU.
The H200 NVL, NVIDIA’s advanced Hopper-based datacenter GPU, boasts 141GB of HBM3e VRAM and 528 Tensor Cores. Engineered for next-generation AI/ML, high-performance computing (HPC), and enterprise workloads, it offers exceptional computational power and energy efficiency with its enhanced memory capacity and bandwidth.
Note: Performance estimates are general guidelines and may vary depending on your AI model, dataset, software, and hardware configuration. For detailed benchmarks, refer to NVIDIA’s official website.
Comparing RTX 3090, RTX 4090, RTX 6000 Ada, and H200 NVL
Choosing the right GPU for AI/ML can be tricky. Use our quick comparison to find the best fit—for reference only.
| Specification | RTX 3090 | RTX 4090 | RTX 6000 Ada | H200 NVL |
| Service Offering | Bare-metal and NovaGPU | Bare-metal and NovaGPU | Bare-metal | NovaGPU |
| Architecture | Ampere | Ada Lovelace | Ada Lovelace | Hopper |
| CUDA Cores | 10,496 | 16,384 | 18,176 | Estimated over 20,000 |
| Tensor Cores | 328 (3rd Gen) | 512 (4th Gen) | 568 (4th Gen) | 1,370 (5th Gen) |
| GPU Memory (VRAM) | 24GB GDDR6X | 24GB GDDR6X | 48GB GDDR6 | 141GB HBM3e |
| Memory Bandwidth | 936 GB/s | 1,008 GB/s | 960 GB/s | 4,800 GB/s |
| FP16 (TFLOPS, Tensor Cores, with Sparsity) | 70 | 661 | 732 | 1,979 |
| INT8 (TOPS, Tensor Cores, with Sparsity) | 140 (INT8) | 1,321 (FP8/INT8) | 1,463 (FP8/INT8) | 3,958 (FP8/INT8) |
| NVLink Support | Yes (2nd Gen) | No | No | Yes (4th Gen) |
| Process Node | 8nm (Samsung) | 4nm (TSMC) | 4nm (TSMC) | 4nm (TSMC) |
| AI Use Case | Small-scale AI training/inference (e.g., 7B LLMs) | Medium-scale AI training/inference (e.g., 13B–22B LLMs) | Large-scale AI training/inference (e.g., 44B LLMs) | Massive-scale AI training/inference (e.g., 100B+ LLMs) |
| Important Notes: |
|
| RTX 3090 | |||||||
| GPU Count | GPU Memory | CPU | Processor | RAM | Bandwidth | Price/Hour | Price/Month |
| 1 GPU | 1 x 24 GB | 8 core | AMD EPYC™ 9124 | 120 GB | 1Gbps | MYR 1.96 | MYR 1,435.02 |
| 2 GPU | 2 x 24 GB | 16 core | AMD EPYC™ 9124 | 240 GB | 1Gbps | MYR 3.92 | MYR 2,870.05 |
| 4 GPU | 4 x 24 GB | 32 core | AMD EPYC™ 9124 | 480 GB | 1Gbps | MYR 7.84 | MYR 5,740.10 |
| RTX 4090 | |||||||
| GPU Count | GPU Memory | CPU | Processor | RAM | Bandwidth | Price/Hour | Price/Month |
| 1 GPU | 1 x 24 GB | 8 core | AMD EPYC™ 9124 | 120 GB | 1Gbps | MYR 2.64 | MYR 1,934.98 |
| 1 GPU | 1 x 48 GB | 8 core | AMD EPYC™ 9124 | 120 GB | 1Gbps | MYR 3.60 | MYR 2,635.50 |
| 2 GPU | 2 x 24 GB | 16 core | AMD EPYC™ 9124 | 240 GB | 1Gbps | MYR 5.29 | MYR 3,869.96 |
| 2 GPU | 2 x 48 GB | 16 core | AMD EPYC™ 9124 | 240 GB | 1Gbps | MYR 7.20 | MYR 5,271.01 |
| 4 GPU | 4 x 24 GB | 32 core | AMD EPYC™ 9124 | 480 GB | 1Gbps | MYR 10.57 | MYR 7,739.92 |
| 4 GPU | 4 x 48 GB | 32 core | AMD EPYC™ 9124 | 480 GB | 1Gbps | MYR 14.40 | MYR 10,542.02 |
| RTX 6000 Ada | |||||||
| GPU Count | GPU Memory | CPU | Processor | RAM | Bandwidth | Price/Hour | Price/Month |
| 1 GPU | 1 x 48 GB | 8 core | AMD EPYC™ 9124 | 120 GB | 1Gbps | MYR 4.84 | MYR 3,535.13 |
| 2 GPU | 2 x 48 GB | 16 core | AMD EPYC™ 9124 | 240 GB | 1Gbps | MYR 9.68 | MYR 7,070.27 |
| H200 NVL | |||||||
| GPU Count | GPU Memory | CPU | Processor | RAM | Bandwidth | Price/Hour | Price/Month |
| 1 GPU | 1 x 141 GB | 32 core | AMD EPYC™ 9354P | 240 GB | 1Gbps | MYR 19.09 | MYR 13,972.33 |
| 2 GPU | 2 x 141 GB | 64 core | AMD EPYC™ 9354P | 480 GB | 1Gbps | MYR 38.18 | MYR 27,944.67 |
| IP Address | Price / Hour |
| One floating IP address associated with a running instance | Free |
| Additional floating IP address associated with a running instance | MYR 0.043 |
| One floating IP address not associated with a running instance | MYR 0.043 |
| One floating IP address remap | Unmetered |
| Data Transfer | Price / Hour / GiB |
| First 1 TiB (*Not applicable to China Premium Route) | Free |
| Up to 10TiB | MYR 0.44 |
| Next 40TiB | MYR 0.31 |
| 50TiB onward | MYR 0.30 |
| Storage | Price / GiB SSD |
| Provision of storage (Inclusive of IOPs) | MYR 0.60 |
| Licensing | Price / Hour |
| Window License | MYR 0.175 |
Enhance your NovaGPU experience with IP ServerOne’s solutions, ensuring seamless performance and peace of mind for your AI journey.
Cloud Computing for Everyone.
Dedicated and Customized Cloud Environment.
Raw Power, Tailored Solutions, Ironclad Security.
A Safe Space for Your Servers and IT Equipment.
Industry: Cybersecurity
Challenge: Security engineers analyze vast volumes of logs and alerts daily, often struggling with false positives and slow threat detection due to data overload.
Solution: AI engineers can use NovaGPU to fine-tune AI models that detect anomalies, classify security events, and enhance real-time threat detection. With GPU-accelerated processing, security teams can quickly filter false positives, prioritize threats, and automate risk assessments for faster and more effective incident response.
Industry: Finance & Accounting
Challenge: Accountants spend hours manually extracting data from PDF invoices, scanned documents, and emails, then inputting it into accounting systems, making the process slow and error-prone.
Solution: AI developers can leverage NovaGPU to train AI-powered invoice processing models that automate text extraction, validation, and data entry. With GPU-accelerated Optical Character Recognition (OCR) and Natural Language Processing (NLP), businesses can eliminate manual work, minimize errors, and accelerate financial workflows.
Industry: AI Chatbot Development
Challenge: Traditional chatbots rely on pre-scripted responses and struggle to retrieve real-time information, often leading to generic or outdated replies.
Solution: AI developers can use NovaGPU to develop Retrieval-Augmented Generation (RAG)-enhanced chatbots that combine real-time data retrieval with generative AI. With GPU-accelerated processing, these chatbots can understand complex queries, fetch up-to-date information, and deliver contextually relevant responses at scale.
GPU as a Service (GPUaaS) is a cloud-based platform that provides on-demand access to high-performance GPUs, eliminating the need for physical hardware. It enables businesses to run AI training, machine learning, and deep learning tasks without upfront costs or infrastructure management. NovaGPU offers flexible, cost-effective GPU instances that can be scaled to meet project demands. Simply sign up, select a plan, and start leveraging powerful GPUs instantly for your AI workloads.
GPU as a Service (GPUaaS) allows users to rent GPU instances on-demand through cloud providers like IP ServerOne. Once subscribed, users can easily spin up instances, scale resources, and pay only for what they use. This model eliminates the need for physical infrastructure, offering flexibility, performance, and accessibility for AI/ML workloads, data analytics, and simulations. With NovaGPU, you can select from various GPU models, the number of GPU cards, storage sizes, and more—all through a secure, managed platform, enabling you to focus on your AI projects.
Both Cloud GPUs and GPU as a Service (GPUaaS) provide access to GPU resources, but the key difference is how they are managed and accessed:
Both GPUaaS and dedicated bare metal GPUs offer powerful computing resources, but they differ in flexibility, cost, and management:
With NovaGPU, you enjoy the flexibility of GPUaaS—high-performance GPUs on demand with no management burden.
GPU as a Service (GPUaaS) is the ideal solution for AI, large language models (LLMs), and deep learning due to the high computational power these tasks require. Unlike traditional CPUs, GPUs are built to handle complex algorithms and process large datasets in parallel, significantly speeding up tasks like model training, fine-tuning, and inference.
NovaGPU provides on-demand, high-performance GPUs, ranging from mid-tier options like the RTX 3090 and RTX 4090 to top-tier models like the RTX 6000 Ada and NVIDIA H200 NVL. Key benefits include:
NovaGPU is ideal for tasks requiring moderate computational power, particularly for AI, machine learning (ML), and deep learning applications. Key use cases include:
With NovaGPU, you get an on-demand, cost-effective, and secure GPU solution tailored to support your small-to-mid-sized AI and ML projects, maximizing performance without overcommitting resources.
Yes, NovaGPU is specifically designed to support machine learning (ML) and AI projects. With its on-demand, scalable GPU instances, NovaGPU provides the computational power needed for tasks like training, fine-tuning, and inference of AI models. Whether you are working on small-to-mid-sized AI models or data processing, NovaGPU delivers high performance at an affordable cost. It’s a perfect fit for developers, researchers, and businesses looking to accelerate their AI and ML workflows without investing in expensive infrastructure.
Choosing the right GPU instance for your workload on NovaGPU depends on your project’s size, complexity, and budget. At IP ServerOne, we offer both bare metal GPUs and GPU as a Service through NovaGPU, tailored for different AI/ML applications. Here’s a guide to help you select the ideal GPU:
Security is a top priority for NovaGPU. We implement multiple layers of protection to ensure the safety and confidentiality of your data and workloads. Key security features include:
With NovaGPU, your sensitive AI projects are securely managed within a robust and reliable cloud environment.
Infrastructure Service & Data Center
Storage
Bare Metal
Email Services
AI
Network
Support Services
Others
Enterprise Solutions
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.